



9.5out of 10
Unified Memory Beast 2026
GMKtec EVO-X2 Mini PC AMD Ryzen AI Max+ 395
$2,699.00
🧠 AMD Ryzen AI Max+ 395 (16 cores, 50 TOPS NPU)
💾 128GB LPDDR5X Unified Memory
🎮 96GB Allocatable as VRAM
🔥 Radeon 8060S iGPU (40 RDNA 3.5 CUs)
💿 2TB PCIe 5.0 NVMe SSD
🌐 WiFi 7 + Bluetooth 5.4
Why Unified Memory Changes Everything
Traditional AI setups need a separate GPU with dedicated VRAM. The EVO-X2's AMD Strix Halo architecture lets the CPU and GPU share the same massive memory pool - allocate up to 96GB as VRAM through AMD software.
96GB
Allocatable VRAM
40
RDNA 3.5 Compute Units
0
External GPU Required
👍 Pros
- ✓ Run 70B+ models at Q8 quantization
- ✓ No eGPU dock required - all-in-one
- ✓ 96GB VRAM crushes 24GB discrete cards for model size
- ✓ Quiet operation - no external GPU fans
- ✓ Simple setup - just power and go
🤔 Considerations
- ○ Slower per-token than RTX 4090
- ○ iGPU less powerful for gaming than discrete
- ○ Premium price point
SPECIFICATIONS
| Processor | AMD Ryzen AI Max+ 395 (16 cores / 32 threads) |
| NPU | 50 TOPS AI accelerator |
| Graphics | Radeon 8060S (40 RDNA 3.5 Compute Units) |
| Memory | 128GB LPDDR5X-8000 (unified pool) |
| Max VRAM Allocation | 96GB via AMD Adrenalin software |
| Storage | 2TB PCIe 5.0 NVMe SSD |
| WiFi | WiFi 7 (802.11be) |
| Bluetooth | 5.4 |
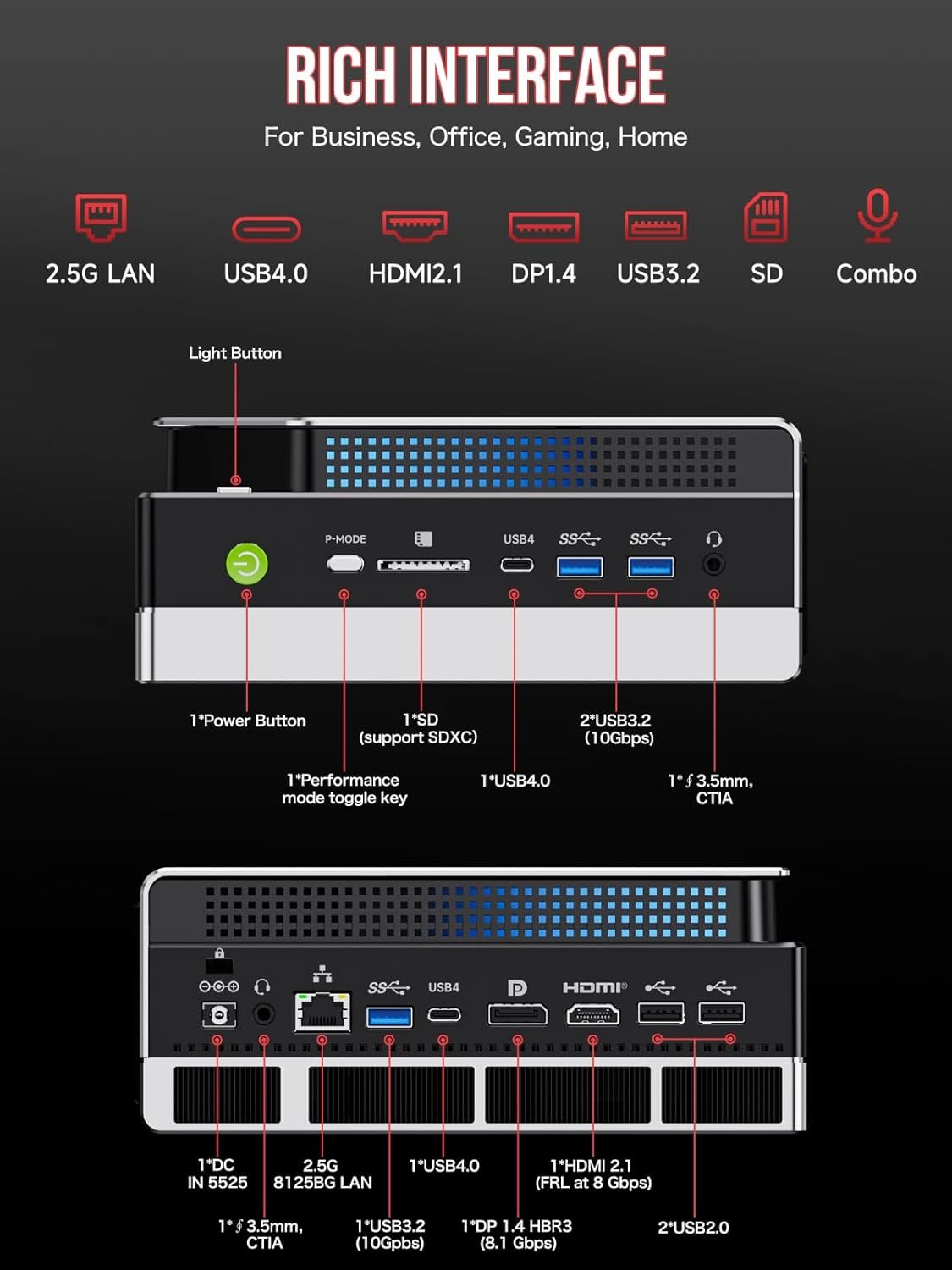
| Ports | USB4, USB-C, HDMI 2.1, DisplayPort 2.1 |
| Power | 120W TDP |
| Dimensions | Compact mini PC form factor |
🧠 What Can You Run?
| DeepSeek 70B Q8 | ✅ Runs natively |
| Llama 3 70B Q6 | ✅ Excellent quality |
| Mixtral 8x22B | ✅ Full model fits |
| Stable Diffusion XL | ✅ Fast generation |
| 100B+ Models (Q4) | ✅ Possible with 96GB |
OUR VERDICT
The GMKtec EVO-X2 represents a paradigm shift in AI workstations. Instead of the traditional Mini PC + eGPU dock approach, AMD's Strix Halo architecture delivers everything in one compact unit. The 128GB unified memory pool - with up to 96GB allocatable as VRAM - means you can run models that simply won't fit on any consumer GPU.
THE UNIFIED MEMORY ADVANTAGE
Traditional discrete GPUs max out at 24GB (RTX 4090) or 32GB (RTX 5090). That limits you to 70B models at Q4 quantization - heavily compressed, lower quality outputs. The EVO-X2's 96GB allocation means the same 70B model runs at Q8 - double the precision, noticeably better responses.
More importantly, you can run 100B+ parameter models that are simply impossible on consumer GPUs. No eGPU dock. No external power supply. No fan noise from a graphics card. Just one compact box.
PERFORMANCE REALITY
Let's be honest: the Radeon 8060S won't match an RTX 4090 in raw tokens-per-second. The 4090's dedicated 24GB of GDDR6X running at 1TB/s bandwidth is faster than shared system memory. Expect roughly 60-70% of 4090 speed on models that fit in 24GB.
But here's the thing - the 4090 can't run what doesn't fit. When your model needs 50GB, 70GB, or 90GB of VRAM, the EVO-X2 is the only consumer option that works.
WHO IS THIS FOR?
- AI researchers needing to run the largest open models locally
- Developers who want a simple, silent all-in-one setup
- Anyone tired of eGPU docks, power supplies, and cable management
- Users who prioritize model quality over raw speed
FINAL SCORE: 9.5/10
The EVO-X2 isn't the fastest. It's the most capable. When VRAM is your bottleneck - and for serious AI work, it always is - this machine delivers what no discrete GPU can.
🔄 EVO-X2 vs eGPU Builds
| EVO-X2 | Mini PC + RTX 4090 | |
| Total Price | $2,699 | $4,500+ |
| Max VRAM | 96GB | 24GB |
| Speed (24GB models) | ~65% | 100% |
| 70B Q8 Support | Yes | No (24GB limit) |
| 100B+ Models | Yes | No |
| Setup Complexity | Plug and play | eGPU dock + cables |
Ready for Unified AI Power?
The future of local AI is here - no external GPU required.
Check Availability on Amazon →